Le AI Overviews di Google rappresentano un cambiamento radicale nel modo in cui i contenuti vengono valutati e presentati agli utenti. Per comprendere come posizionarsi in queste nuove risposte generate dall’intelligenza artificiale, è necessario andare oltre la superficie e capire i meccanismi fondamentali che governano la selezione dei contenuti.
Dal testo ai vettori: lo spazio vettoriale degli embeddings
Gli embeddings sono rappresentazioni matematiche che trasformano parole, frasi o interi documenti in vettori numerici multidimensionali. Pensali come coordinate che posizionano ogni concetto in uno spazio geometrico dove il significato diventa misurabile.
Come funzionano: dal testo ai numeri
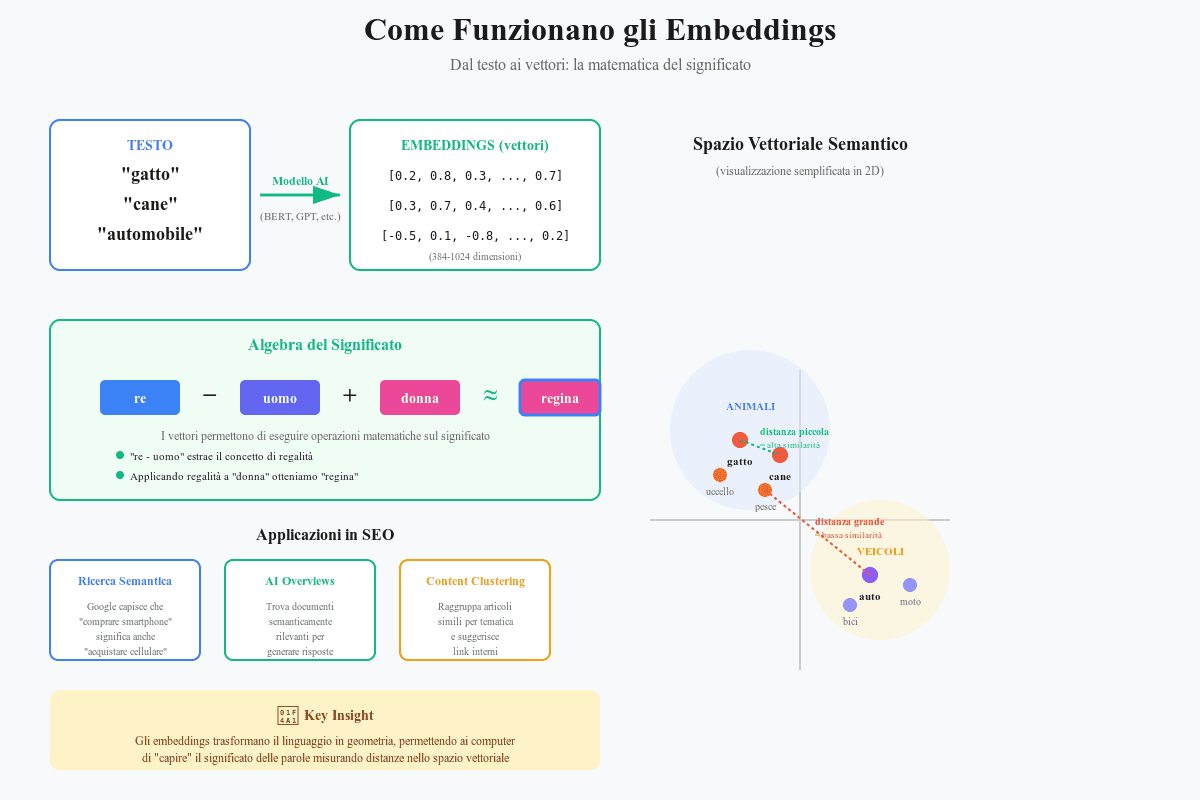
Quando scrivi la parola “gatto”, un modello linguistico la converte in un vettore del tipo:
“gatto” → [0.21, -0.45, 0.67, 0.12, …, 0.33]
Questo vettore tipicamente ha da 384 a 1024 dimensioni (non solo 5 come nell’esempio), e ogni dimensione cattura un aspetto diverso del significato: animale domestico, mammifero, piccolo, felino, e così via.
Quando Google converte il tuo contenuto in embeddings, non conta semplicemente le parole, ma mappa il significato del testo in uno spazio geometrico multidimensionale. Ogni modello assegna un numero di dimensioni diverso: nei Transformer classici (es. BERT) sono tipicamente 768 o 1024, mentre nei modelli più recenti possono superare le 1.500.
Immagina per un momento di poter comprimere questo spazio in 3 dimensioni visibili. In questo spazio ipotetico:
- La parola “automobile” occupa un punto specifico
- Nelle immediate vicinanze trovi “vettura”, “auto”, “veicolo”
- Poco più distante, ma sempre nella stessa regione, trovi “macchina”, “automezzo”
- In una zona adiacente si trovano concetti correlati come “guidare”, “strada”, “motore”
- Molto più lontani, in altre regioni dello spazio, trovi concetti non correlati come “fotografia” o “cucina”
Cluster semantici: come si organizzano i concetti
Nello spazio vettoriale, i concetti si organizzano naturalmente in cluster tematici. Questo fenomeno ha implicazioni pratiche fondamentali, vediamolo in un altro esempio:
Cluster del marketing digitale:
- Centro del cluster: “digital marketing”, “marketing online”
- Prima corona: “SEO”, “SEM”, “social media marketing”, “content marketing”
- Seconda corona: “Google Ads”, “Facebook Ads”, “email marketing”, “influencer marketing”
- Terza corona: termini tecnici specifici come “CTR”, “conversion rate”, “funnel”
Perché questo è importante per il tuo contenuto:
Quando scrivi un articolo sul SEO, Google non valuta solo se usi la parola “SEO”, ma se il tuo contenuto si posiziona nel cluster semantico corretto. Un articolo che parla di SEO ma usa terminologia correlata (ottimizzazione motori di ricerca, posizionamento organico, ranking, SERP, backlink) si posizionerà più centralmente nel cluster rispetto a uno che ripete meccanicamente “SEO” senza contestualizzazione semantica.
Test pratico: verifica la ricchezza semantica del tuo contenuto
Prendi un tuo articolo e fai questo esperimento:
- Identifica il concetto centrale (es. “email marketing”)
- Elenca i termini correlati che dovrebbero apparire in un contenuto completo:
- Sinonimi diretti: “newsletter”, “DEM”, “email campaigns”
- Concetti correlati primari: “list building”, “segmentazione”, “automation”
- Concetti correlati secondari: “open rate”, “deliverability”, “A/B testing”
- Termini tecnici: “SMTP”, “bounce rate”, “soft bounce vs hard bounce”
- Conta quanti di questi termini appaiono naturalmente nel tuo contenuto
- Valuta la distribuzione: Sono concentrati in una sezione o distribuiti organicamente?
Se il tuo contenuto copre meno del 60-70% dei termini correlati attesi, probabilmente si posiziona nella periferia del cluster semantico, non al centro. Questo riduce la probabilità che venga selezionato come fonte autorevole dal sistema di retrieval.
Implicazioni pratiche: sinonimi e variazioni
Ecco un concetto controintuitivo ma fondamentale: nell’era degli embeddings, scrivere “automobile”, “vettura”, “auto” o “veicolo” porta allo stesso identico risultato in termini di pertinenza semantica.
Questo significa:
Non serve più:
- Ripetere ossessivamente la keyword esatta
- Creare variazioni artificiali (“auto nuove”, “nuove auto”, “automobili nuove”)
- Sacrificare la leggibilità per la densità di keyword
Diventa invece importante:
- Coprire l’ampiezza semantica del cluster
- Usare terminologia naturale e varia
- Includere concetti correlati che arricchiscono il contesto
Esempio concreto:
Approccio vecchio (keyword-focused): “Le automobili elettriche sono il futuro. Le automobili elettriche offrono vantaggi. Le automobili elettriche riducono emissioni. Acquistare automobili elettriche conviene.”
Approccio moderno: “I veicoli elettrici rappresentano il futuro della mobilità. Le auto a batteria offrono vantaggi economici significativi, riducendo le emissioni inquinanti rispetto ai mezzi tradizionali a combustione. L’acquisto di un’EV conviene grazie agli incentivi governativi e ai minori costi di manutenzione.”
Il secondo esempio usa variazioni naturali (veicoli elettrici, auto a batteria, EV) e introduce concetti correlati (batteria, combustione, incentivi, manutenzione) che lo posizionano più centralmente nel cluster semantico delle “auto elettriche”.
Recall vs Precision: perché Google usa due sistemi diversi
Google deve processare query su un indice di centinaia di miliardi di pagine web. Questo crea un problema fondamentale di efficienza computazionale.
Scenario ipotetico:
- Query: “Come coltivare pomodori in vaso”
- Documenti nell’indice: 500 miliardi
- Documenti potenzialmente rilevanti: forse 10 milioni
- Documenti realmente ottimali: forse 50-100
Il problema è: come identificare quei 50-100 documenti ottimali senza analizzare approfonditamente tutti i 500 miliardi?
La soluzione: pipeline a due stadi
Google risolve questo problema con un approccio a imbuto:
Stadio 1 – Recall (Bi-encoder):
- Obiettivo: Non perdere nessun documento potenzialmente rilevante
- Priorità: Velocità e copertura massima
- Tolleranza: Accetta falsi positivi (documenti non realmente rilevanti che passano il filtro)
- Output: Da 500 miliardi a circa 1000-10.000 candidati
Stadio 2 – Precision (Cross-encoder/Reranker):
- Obiettivo: Identificare i documenti più rilevanti con massima accuratezza
- Priorità: Precisione assoluta
- Tolleranza: Zero falsi positivi
- Output: Da 1000-10.000 a 10-50 fonti finali
Analogia pratica: la pesca con due reti
Immagina di pescare in un oceano enorme cercando pesci di una specie rara specifica:
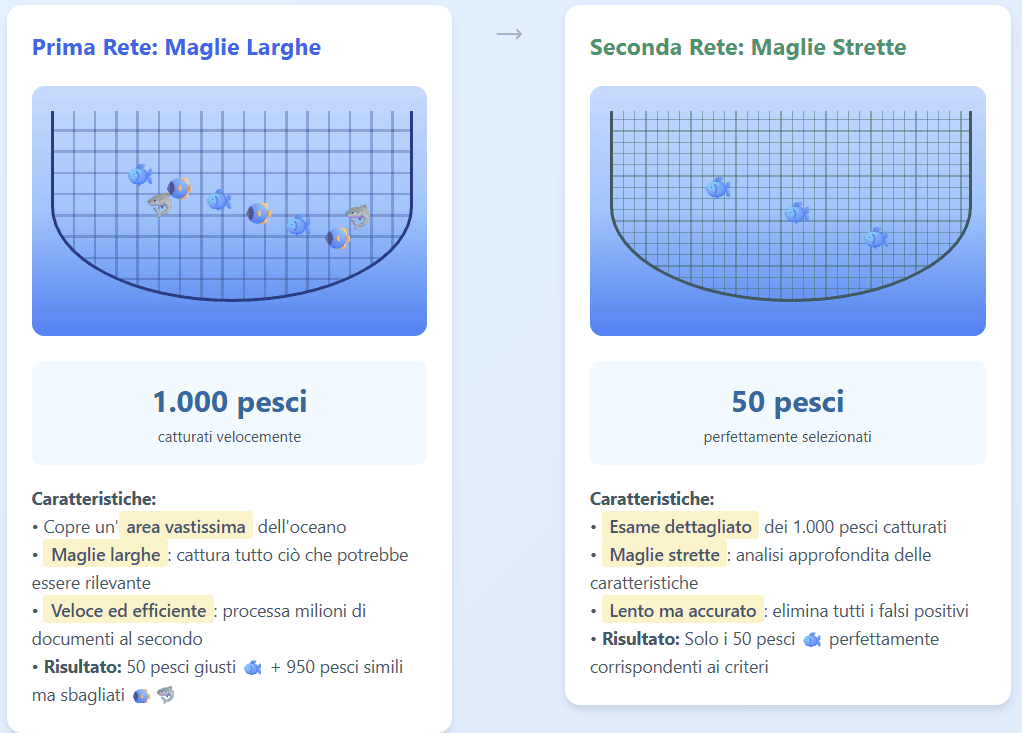
Prima rete (Recall):
- Rete a maglie larghe che copre un’area vastissima
- Cattura tutto ciò che ha una vaga somiglianza con quello che cerchi
- Veloce, efficiente, ma cattura anche molti pesci “sbagliati”
- Risultato: 1000 pesci di cui 50 sono quelli giusti e 950 sono simili ma non corretti
Seconda rete (Precision):
- Esame dettagliato dei 1000 pesci catturati
- Analisi approfondita delle caratteristiche specifiche
- Lento, accurato, elimina tutti i falsi positivi
- Risultato: 50 pesci perfettamente corrispondenti ai criteri
Perché servono entrambe le reti?
Se usassimo solo la rete fine (cross-encoder) su tutto l’oceano (500 miliardi di documenti), impiegheremmo 1.585 anni per analizzare tutto. Con la pipeline a due stadi, otteniamo la stessa qualità in meno di 1 secondo. La prima rete riduce rapidamente il volume, la seconda garantisce la qualità assoluta del risultato finale.
Costi computazionali: perché serve questa architettura
Facciamo un calcolo semplificato per capire perché Google non può usare solo il reranker:
Scenario con solo cross-encoder (reranker su tutto):
- Documenti da analizzare: 500 miliardi
- Tempo per analisi di ogni coppia query-documento: 100ms
- Tempo totale: 500.000.000.000 × 0.1s = 50 miliardi di secondi = 1.585 anni
Scenario con pipeline ibrida:
- Fase 1 (Bi-encoder): 500 miliardi × 0.001ms = 500.000 secondi = 5,8 giorni
- Fase 2 (Cross-encoder): 10.000 × 100ms = 1.000 secondi = 16 minuti
- Tempo totale effettivo con parallelizzazione: < 1 secondo
La differenza è abissale. Senza il bi-encoder per il recall veloce, le AI Overviews sarebbero impossibili da generare in tempo reale.
Implicazioni per la tua strategia di contenuto
Comprendere questo sistema a due stadi cambia radicalmente come devi ottimizzare:
Per superare la fase di Recall (bi-encoder):
- Ampiezza semantica: copri tutti i concetti correlati al tema
- Completezza tematica: tratta l’argomento in modo esaustivo
- Ricchezza terminologica: usa sinonimi e variazioni naturali
- Copertura delle long-tail: includi domande specifiche correlate
Per eccellere nella fase di Precision (reranker):
- Risposte dirette: fornisci risposte chiare a domande specifiche
- Struttura estraibile: paragrafi autonomi e comprensibili fuori contesto
- Specificità: dati concreti, esempi, metriche
- Rilevanza contestuale: allineamento perfetto tra domanda e risposta
Caso pratico: ottimizzazione a due livelli
Query target: “Quanto costa realizzare un e-commerce”
Ottimizzazione per recall: il tuo contenuto deve includere naturalmente:
- Termini semanticamente correlati: “sito web”, “piattaforma”, “negozio online”, “vendita online”
- Concetti correlati: “Shopify”, “WooCommerce”, “Magento”, “hosting”, “payment gateway”
- Variazioni dell’intento: “costi”, “prezzi”, “investimento”, “budget necessario”
Questo garantisce che il bi-encoder identifichi il tuo contenuto come candidato rilevante.
Ottimizzazione per precision: Una volta selezionato come candidato, devi vincere il reranking con:
“Il costo per realizzare un e-commerce varia da 3000€ a 50.000€ in base alla complessità. Per un negozio base con Shopify o WooCommerce, il budget iniziale è di 3000 – 5.000€ (template, dominio, hosting). Per soluzioni custom con Magento o sviluppo proprietario, l’investimento parte da 15.000-50.000€ includendo design personalizzato, integrazioni avanzate e funzionalità su misura. I costi ricorrenti annuali vanno da 200€ (soluzione base) a 5.000€+ (piattaforme enterprise).”
Questo paragrafo:
- Risponde direttamente alla query con numeri specifici
- Include range di prezzi concreti
- Distingue scenari diversi con criteri chiari
- Menziona piattaforme specifiche
- È estraibile e comprensibile autonomamente
Input congiunto vs elaborazione separata: la differenza architetturale
Come funziona il bi-encoder
Nel sistema bi-encoder:
- Query → Encoder A → Vettore Query [0.2, 0.8, 0.3, …]
- Documento → Encoder B → Vettore Documento [0.25, 0.75, 0.35, …]
- Confronto: calcolo della cosine similarity tra i due vettori
Caratteristiche chiave del bi-encoder:
- I due encoder lavorano indipendentemente
- Non c’è “comunicazione” tra query e documento durante l’encoding
- Il confronto avviene solo alla fine, matematicamente
- Veloce perché i vettori dei documenti possono essere pre-calcolati
Come funziona il cross-encoder
Nel sistema cross-encoder:
- Input congiunto: “[Query] Come coltivare pomodori [SEP] [Documento] I pomodori richiedono terreno ben drenato, esposizione solare diretta per almeno 6 ore…”
- Elaborazione simultanea: il modello transformer analizza query e documento insieme
- Meccanismo di attenzione: ogni parola della query “guarda” ogni parola del documento
- Output: Punteggio di rilevanza diretto [0-1]
Caratteristiche chiave:
- Query e documento sono processati simultaneamente
- Il modello vede le relazioni tra termini in tempo reale
- Cattura dipendenze complesse e sfumature contestuali
- Molto più lento perché non può pre-calcolare nulla
Esempio pratico della differenza
Query: “Python è adatto per machine learning?”
Documento A: “Python è un linguaggio di programmazione versatile utilizzato in molti campi, incluso il machine learning dove è molto popolare.”
Documento B: “Java è un linguaggio robusto per applicazioni enterprise. Python, pur essendo interpretato, offre librerie come TensorFlow e scikit-learn che lo rendono ideale per machine learning.”
Analisi con Bi-encoder (elaborazione separata):
Entrambi i documenti:
- Contengono “Python” ✓
- Contengono “machine learning” ✓
- Hanno alta cosine similarity con la query
Punteggi: A = 0.87, B = 0.85 (molto simili)
Analisi con Cross-encoder (input congiunto):
Il modello analizza le relazioni:
Documento A:
- “Python” → “machine learning”: connessione diretta
- “adatto”/”utilizzato in”: allineamento con la query “è adatto per”
- Risposta implicita: SÌ
Documento B:
- “Python” → “machine learning”: connessione mediata da “librerie”
- “Java” introduce rumore iniziale
- “ideale per machine learning”: forte allineamento semantico con “adatto per”
- Risposta esplicita: SÌ, con evidenze (TensorFlow, scikit-learn)
Punteggi reranking: A = 0.78, B = 0.92
Il cross-encoder capisce che B, nonostante menzioni Java inizialmente, fornisce una risposta più completa e supportata da evidenze concrete.
Perché l’input congiunto cattura meglio il contesto
Il meccanismo di attenzione nel cross-encoder crea una “mappa di relazioni” tra query e documento:
Query: “migliori plugin WordPress per SEO”
Documento: “Yoast SEO è il plugin più popolare per ottimizzare WordPress. Offre analisi keyword, sitemap XML e meta description.”
Mappa di attenzione (semplificata):
- “plugin” → “Yoast SEO” (forte)
- “plugin” → “plugin” (molto forte)
- “WordPress” → “WordPress” (perfetto match)
- “WordPress” → “ottimizzare” (correlazione contestuale)
- “SEO” → “SEO” (perfetto match)
- “SEO” → “ottimizzare” (sinonimia contestuale)
- “migliori” → “più popolare” (allineamento valutativo)
- “SEO” → “keyword”, “sitemap”, “meta description” (evidenze specifiche)
Il bi-encoder vedrebbe semplicemente che query e documento condividono termini simili. Il cross-encoder capisce che il documento risponde alla query con un esempio specifico (Yoast) e fornisce evidenze della sua idoneità (funzionalità SEO specifiche).
Dall’era delle keyword all’era degli embeddings: evoluzione storica
Timeline dell’evoluzione algoritmica di Google
1998-2010: L’era del keyword matching
- Google valutava principalmente la presenza e frequenza di keyword esatte
- Tecniche dominanti: keyword density, exact match domains, anchor text
- Limiti: vulnerabile a manipolazione, non capiva sinonimi o contesto
2011-2012: Panda e Penguin
- Focus sulla qualità dei contenuti e profilo backlink naturale
- Penalizzazione di keyword stuffing e thin content
- Inizio della valutazione semantica superficiale
2013: Hummingbird
- Primo tentativo di comprendere il significato dietro le query
- Introduzione del “conversational search”
- Ancora limitato nella comprensione contestuale
2015: RankBrain
- Introduzione del machine learning per interpretare query
- Primi embeddings rudimentali per matching semantico
- Capacità di gestire query mai viste prima
2018-2019: BERT
- Comprensione bidirezionale del contesto
- Capacità di capire sfumature come negazioni, condizionali, relazioni
- Analisi della query nel suo insieme, non parola per parola
2021-2023: MUM e embeddings avanzati
- Comprensione multilingue e multimodale
- Embeddings di alta qualità per matching semantico profondo
- Capacità di rispondere a query complesse multi-step
2024-presente: AI Overviews
- Sintesi di informazioni da multiple fonti
- Pipeline ibrida bi-encoder/cross-encoder
- Generazione di risposte contestualizzate e verificate
Cosa funzionava prima e perché non funziona più
Tecniche obsolete:
- Keyword stuffing
- Cosa era: Ripetere la keyword target 20-30 volte in un articolo breve
- Perché funzionava: Gli algoritmi contavano le occorrenze letterali
- Perché non funziona più: Gli embeddings catturano il significato, non contano le parole
- Exact match domains
- Cosa era: Comprare domini come “migliori-scarpe-running.com”
- Perché funzionava: Segnale forte di rilevanza per quella keyword
- Perché non funziona più: I reranker valutano la qualità del contenuto, non il dominio
- Doorway pages
- Cosa era: Pagine ottimizzate per keyword specifiche con contenuto minimo
- Perché funzionava: Matching keyword esatto portava traffico
- Perché non funziona più: La rilevanza contestuale richiede contenuto sostanziale
- Article spinning
- Cosa era: Creare variazioni di un articolo sostituendo sinonimi
- Perché funzionava: Sembravano contenuti diversi agli algoritmi testuali
- Perché non funziona più: Gli embeddings riconoscono contenuti semanticamente identici
- Anchor text over-optimization
- Cosa era: Link con anchor text exact match (“scarpe running economiche”)
- Perché funzionava: Segnale diretto di rilevanza per quella frase
- Perché non funziona più: I sistemi moderni valutano l’autorità contestuale complessiva
Tecniche moderne che “funzionano”
- Topic clustering
- Creare hub di contenuti interconnessi su un tema
- Coprire l’intero cluster semantico, non singole keyword
- Dimostrare expertise approfondita
- Semantic richness
- Usare naturalmente sinonimi, variazioni, concetti correlati
- Scrivere per umani, non per algoritmi
- Includere esempi, casi studio, dati concreti
- Intent matching
- Allineare il contenuto all’intento specifico della query
- Fornire esattamente ciò che l’utente cerca
- Strutturare le informazioni per facilitare l’estrazione
- E-E-A-T (Experience, Expertise, Authoritativeness, Trust)
- Dimostrare competenza attraverso profondità e accuratezza
- Citare fonti autorevoli e dati verificabili
- Aggiornare contenuti regolarmente
Comprendere gli intenti di ricerca nel contesto del reranking
Tassonomia degli intenti
Il reranker non valuta solo se un contenuto è semanticamente rilevante, ma se risponde all’intento specifico dietro la query.
- Intento Informativo
- L’utente cerca di capire, imparare, conoscere
- Query tipo: “cos’è”, “come funziona”, “perché”, “differenza tra”
- Contenuto ideale: Spiegazioni chiare, definizioni, tutorial
- Intento Navigazionale
- L’utente cerca un sito o risorsa specifica
- Query tipo: “Facebook login”, “YouTube”, “sito Nike”
- Contenuto ideale: Link diretto alla risorsa cercata
- Intento Transazionale
- L’utente è pronto ad acquistare o compiere un’azione
- Query tipo: “comprare”, “prezzo”, “sconto”, “dove acquistare”
- Contenuto ideale: Schede prodotto, comparazioni prezzi, call-to-action
- Intento Commerciale
- L’utente sta valutando opzioni prima di decidere
- Query tipo: “migliori”, “recensioni”, “vs”, “alternative”
- Contenuto ideale: Comparazioni dettagliate, pro/contro, recensioni
Come il reranker valuta l’allineamento intento-contenuto
Query: “miglior smartphone 2025”
Intento identificato: Commerciale – l’utente vuole confrontare opzioni prima di acquistare
Documento A – Basso allineamento: “Gli smartphone sono dispositivi mobili che permettono di comunicare, navigare e usare applicazioni. La tecnologia degli smartphone è in continua evoluzione…”
- Informativo generico
- Non risponde all’intento commerciale
- Nessuna comparazione o raccomandazione
- Punteggio reranking: 0.3
Documento B – Alto allineamento: “I migliori smartphone del 2025 sono:
- iPhone 17 Pro – Eccellente per fotografia (€1.299)
- Samsung Galaxy S25 Ultra – Miglior display (€1.199)
- Google Pixel 10 Pro – Migliore AI integrata (€999)
[Seguono comparazioni dettagliate di specifiche, prezzi, pro/contro]”
- Risponde direttamente all’intento commerciale
- Fornisce opzioni concrete con prezzi
- Include criteri di valutazione
- Punteggio reranking: 0.92
Query ambigue e interpretazione contestuale
Alcune query possono avere intenti multipli. Il reranker deve interpretare correttamente:
Query: “Python”
Possibili intenti:
- Informativo: Vuole informazioni sul linguaggio di programmazione
- Navigazionale: Cerca il sito ufficiale python.org
- Informativo (animale): Cerca informazioni sul serpente pitone
Il reranker usa segnali contestuali per disambiguare:
- Profilo utente: Sviluppatore vs non-tecnico
- Query precedenti nella sessione
- Pattern di comportamento
- Localizzazione geografica
Query con contesto: “Python tutorial for beginners” → Intento chiaramente informativo su programmazione
Query senza contesto: “Python” → Il reranker deve fare inferenza probabilistica
Ottimizzare per intenti multipli
Per query ambigue, la strategia migliore è:
- Chiarisci subito il contesto nel titolo e primi paragrafi
- Usa disambiguatori se necessario (“Python (linguaggio di programmazione)”)
- Fornisci completezza per l’intento principale
- Menziona brevemente altri significati se pertinenti
Esempio per “Python”:
“Python: Guida Completa al Linguaggio di Programmazione
Python è un linguaggio di programmazione ad alto livello utilizzato per sviluppo web, data science, machine learning e automazione. [Contenuto principale per programmatori]
Nota: Questo articolo tratta del linguaggio Python. Per informazioni sul serpente pitone, vedi [link].”
Questo approccio:
- Disambigua immediatamente
- Ottimizza per l’intento primario (programmazione)
- Riconosce l’ambiguità senza diluire il focus
Conclusione: dalla teoria alla strategia operativa
Comprendere embeddings, spazio vettoriale, recall vs precision e intenti di ricerca non è un esercizio accademico. È la base per una strategia SEO efficace nell’era delle AI Overviews.
Principi operativi chiave:
- Pensa in termini di cluster semantici, non keyword isolate
- Ottimizza per recall & precision con approcci specifici per ciascuno
- Allinea contenuto e intento con precisione chirurgica (fondamentale ed aspetto più complesso)
- Arricchisci semanticamente i contenuti con terminologia naturale
- Struttura per estraibilità con risposte dirette e autonome
Il futuro del SEO appartiene a chi crea contenuti genuinamente rilevanti contestualmente, non a chi cerca scorciatoie algoritmiche. Gli embeddings e i reranker sono progettati per premiare qualità, completezza e utilità reale.
Il tuo obiettivo non è “ingannare” il sistema, ma diventare la fonte più autorevole e utile nel tuo cluster semantico di riferimento.
FAQ – Come le AI Overviews selezionano i contenuti
Cosa sono gli embeddings e perché sono importanti per la SEO?
Gli embeddings sono rappresentazioni numeriche del testo in uno spazio multidimensionale. In pratica, Google trasforma parole, frasi e documenti in vettori di numeri che catturano il loro significato. Questo consente di misurare la somiglianza semantica tra una query e un contenuto.
Per la SEO significa che non conta solo ripetere la keyword, ma coprire l’intero cluster semantico di un argomento (sinonimi, varianti, concetti correlati).
Qual è la differenza tra pertinenza semantica e rilevanza contestuale?
- Pertinenza semantica → misura quanto il contenuto è vicino alla query a livello di significato (grazie agli embeddings e alla cosine similarity).
- Rilevanza contestuale → valuta se il contenuto risponde esattamente all’intento dell’utente, considerando contesto, relazioni tra parole e sfumature.
Un testo può essere semanticamente pertinente ma non contestualmente rilevante (es. parla di “auto elettriche” ma non risponde alla domanda “quanto costano”).
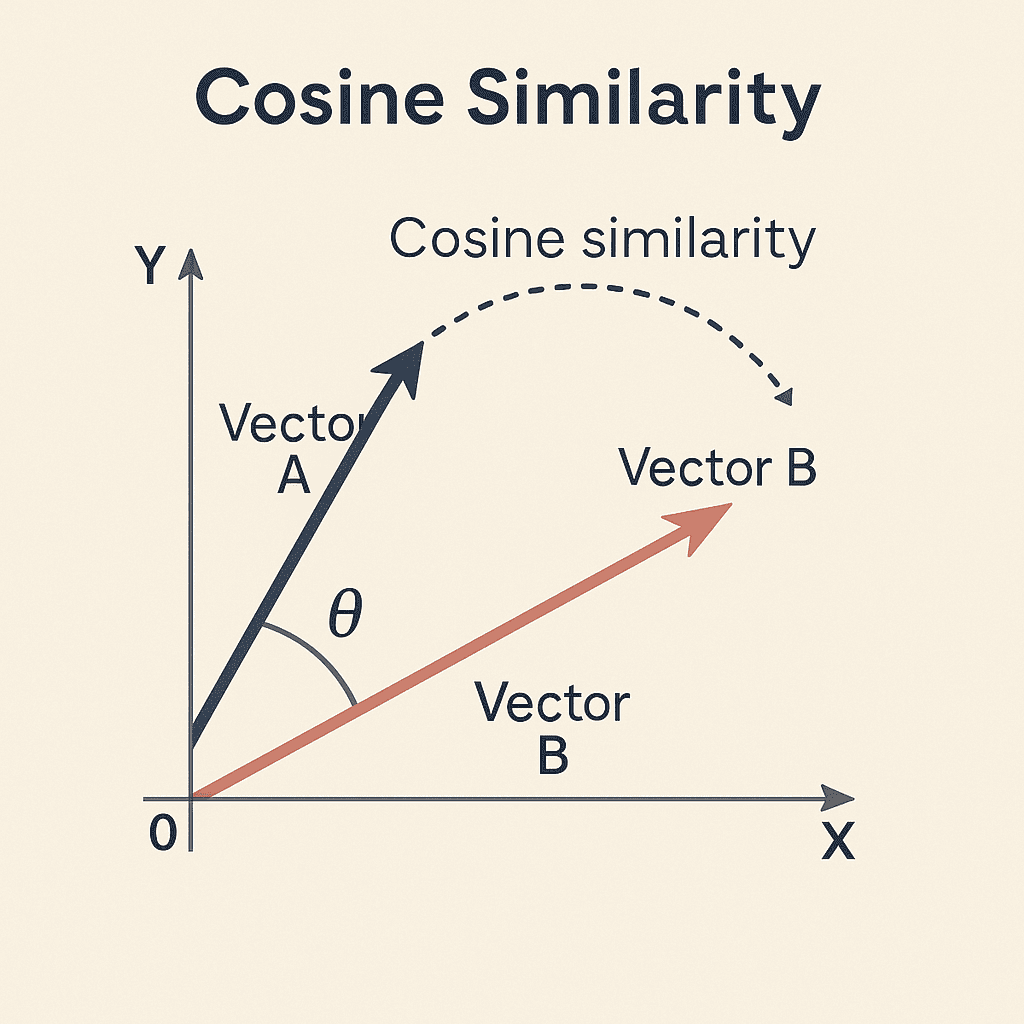
Come funziona la cosine similarity?
La cosine similarity calcola l’angolo tra il vettore della query e quello del documento nello spazio multidimensionale.
- Un angolo piccolo (vicino a 0°) = alta somiglianza → contenuto pertinente.
- Un angolo grande = bassa somiglianza → contenuto poco rilevante.
È uno strumento matematico che Google usa nella fase iniziale di recupero semantico dei documenti.
Cosa sono bi-encoder e cross-encoder?
- Bi-encoder: elaborano query e documento separatamente, producono embeddings e li confrontano con la cosine similarity. Sono veloci, scalabili, ma meno precisi.
- Cross-encoder: analizzano query e documento insieme (input congiunto) grazie al meccanismo di attenzione dei Transformer, catturando sfumature e relazioni complesse. Sono più precisi ma più costosi
Perché Google usa sia bi-encoder che cross-encoder?
Perché deve bilanciare velocità e precisione:
- I bi-encoder filtrano miliardi di documenti, riducendoli a migliaia di candidati (fase di recall).
- I cross-encoder con reranker raffinano la selezione, scegliendo le fonti più precise e contestualmente rilevanti (fase di precision).
Questa architettura ibrida permette di generare risposte affidabili in pochi istanti.
Cos’è un reranker e che ruolo ha nelle AI Overviews?
Il reranker è un modello linguistico che assegna un punteggio di rilevanza a ogni documento candidato. Lavora confrontando query e documento a livello contestuale, decidendo quali contenuti sono davvero i più utili per rispondere.
Nelle AI Overviews di Google, il reranker è ciò che determina se la tua pagina entra tra le fonti mostrate oppure no.
Perché i sinonimi e le variazioni naturali sono fondamentali per il SEO moderno?
Perché con gli embeddings, termini diversi ma con lo stesso significato (“auto”, “automobile”, “veicolo”) vengono posizionati nello stesso cluster semantico.
- Non serve più ripetere ossessivamente la keyword esatta.
- Conta invece arricchire il testo con concetti correlati, esempi, variazioni terminologiche e terminologia naturale.
Questo aumenta le probabilità che il contenuto sia visto come completo e autorevole dal modello.
Perché il bi-encoder viene associato al concetto di “recall”?
Nel linguaggio del information retrieval, recall significa la capacità di recuperare quanti più documenti potenzialmente rilevanti possibile.
Il bi-encoder funziona esattamente così: trasforma query e documenti in embeddings e li confronta tramite cosine similarity, selezionando rapidamente un set ampio di candidati.
- Vantaggio: è veloce e scalabile, ideale per non perdere nessuna possibile fonte.
- Limite: include anche documenti meno pertinenti (falsi positivi), che verranno poi filtrati dal cross-encoder e dal reranker nella fase di precision.
Come si può ottimizzare un contenuto per superare la fase di recall?
Per superare la selezione iniziale dei bi-encoder, un contenuto deve:
- Coprire ampiezza semantica (sinonimi, concetti primari e secondari).
- Offrire completezza tematica (articoli esaustivi, non superficiali).
- Includere terminologia naturale usata nel settore.
- Rispondere anche a long-tail query
Come posso ottimizzare i miei contenuti per le AI Overviews?
Per avere più chance di comparire come fonte nelle AI Overviews, lavora su due livelli:
Recall (bi-encoder):
- Copri l’argomento in modo esaustivo.
- Usa sinonimi, concetti primari e secondari.
- Includi long-tail query correlate.
Precision (reranker):
- Fornisci risposte dirette e autonome.
- Usa dati concreti, esempi, numeri.
- Allinea il contenuto in modo preciso all’intento di ricerca.


